# Initialisation
Considérez la Boîte d'Initialisation (voir l'exemple ci-dessous) comme votre point de départ, qui contient tous les composants clés nécessaires pour configurer votre pipeline d'apprentissage automatique. À l'intérieur, vous pouvez utiliser quatre nœuds essentiels :
* **Ensemble de données**: Définissez les données de votre pipeline pour commencer.
* **Nettoyer**: Mettez vos données en ordre pour de meilleurs résultats.
* **Diviser**: Divisez vos données en entraînement et test.
* **Modèle**: Sélectionnez et configurez votre modèle d'apprentissage automatique.
Exemple d'une Boîte d'Initialisation
## **Nœud Ensemble de données : point de départ de votre expérience**
Le **Ensemble de données** nœud marque le début de votre expérience ; ici, vous définissez les données que votre pipeline utilisera. Dans le flux de travail d'apprentissage automatique, cela représente l'ensemble d'apprentissage comme illustré ci-dessous :
**Types de données disponibles**
Vous disposez de deux options flexibles pour charger vos données :
1. **Standard MEDomics**
* Récupère automatiquement les fichiers d'un dossier d'apprentissage désigné (généralement prétraités `.csv` fichiers du [flux de travail MEDprofiles](https://medomicslab.gitbook.io/medomics-docs/v1-fr/tutorials/design/input-module/medprofiles) ).
* Le nœud détecte les fichiers compatibles et les liste dans un menu déroulant.
* Sélectionnez votre(vos) fichier(s), puis spécifiez la **colonne cible** (la variable que vous souhaitez prédire).
* *Astuce pro :* Si vous sélectionnez plusieurs fichiers, assurez-vous qu'ils partagent tous la même colonne cible.
2. **Fichier personnalisé**
* Téléversez n'importe quel `.csv` fichier depuis votre espace de travail en utilisant le sélecteur déroulant.
* Tout comme avec Standard MEDomics, choisissez votre **colonne cible** pour définir l'objectif de prédiction.
**Options du nœud**
Les options de ce nœud reflètent les paramètres non liés au nettoyage de [PyCaret `setup()` fonction](https://pycaret.readthedocs.io/en/latest/api/classification.html#pycaret.classification.setup).
Répartition du nœud Ensemble de données
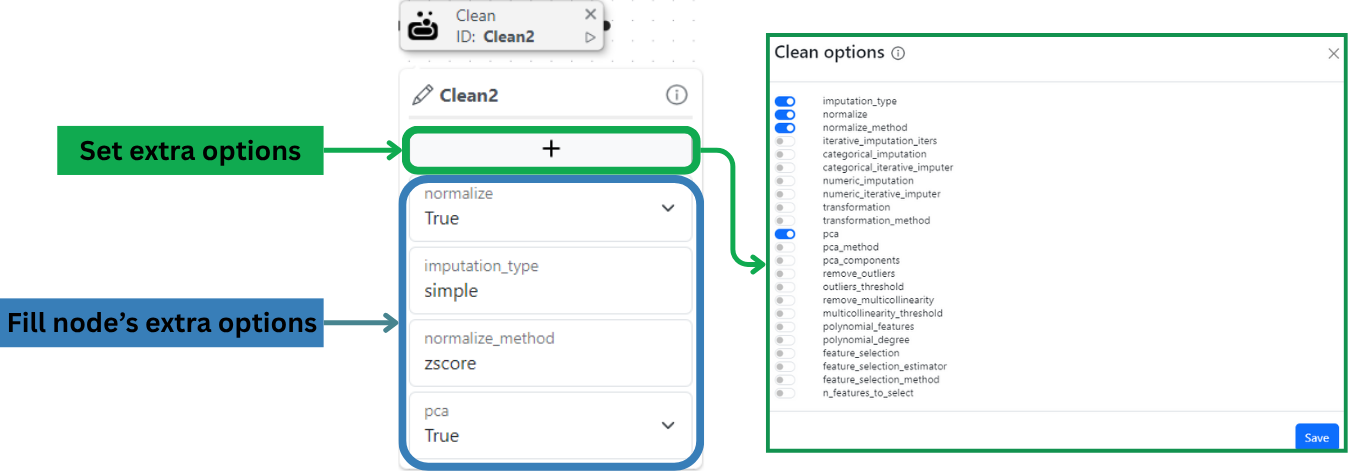
## Nœud Nettoyer : organiser et transformer vos données
Ce nœud vous aide à organiser et transformer votre ensemble de données avant l'entraînement du modèle. Utilisez-le pour gérer les problèmes de données courants, tels que les valeurs manquantes, la mise à l'échelle, et plus encore, afin que votre modèle reçoive la meilleure entrée possible. Dans le flux de travail d'apprentissage automatique, le nœud de Nettoyage est utilisé pour définir l'étape de l'ensemble d'apprentissage, comme illustré ci-dessous :
Les options disponibles pour ce nœud correspondent aux [*options* setup*()* de PyCaret](https://pycaret.readthedocs.io/en/latest/api/classification.html#pycaret.classification.setup) spécialement conçues pour le nettoyage des données.
Répartition du nœud Nettoyer
## Nœud Diviser : définissez vos partitions d'entraînement et de test
Ce nœud est essentiel pour concevoir la manière dont votre ensemble d'apprentissage sera divisé pour l'entraînement et le test. Sans lui, les modèles utilisent par défaut une seule **itération** **de**. Dans la nouvelle architecture, le nœud Diviser est utilisé dans l'étape de partitionnement de l'ensemble d'apprentissage, comme montré ci-dessous :
Un partitionnement approprié des données prévient les fuites d'information et fournit des estimations de performance fiables — crucial pour des résultats ML dignes de confiance. Vous pouvez choisir parmi ces méthodes de partitionnement :
1. **Validation croisée (K-Fold)**
* Divise les données en *K* plis égaux, en utilisant *K-1* pour l'entraînement et 1 pour le test à chaque itération
* Idéal pour : jeux de données petits à moyens, maximisant l'utilisation des données
* Pratique courante : configurations à 5 plis ou 10 plis
* Options à définir :
* **num\_folds**: nombre de plis à utiliser (*K*).
2. **Sous-échantillonnage aléatoire**
* Divise les données au hasard en pourcentages fixes d'entraînement/test (par ex., 80%/20%)
* Idéal pour : grands jeux de données, prototypage rapide
* Astuce : l'échantillonnage stratifié maintient les proportions des classes
* Options à définir :
* **test\_size**: Proportion des données à allouer à l'ensemble de test (doit être comprise entre 0 et 1).
* **n\_iterations**: Nombre de répétitions, c'est-à-dire le nombre de divisions à créer. Augmenter les répétitions peut réduire l'incertitude des estimations de performance.
3. **Bootstrap**
* Crée plusieurs échantillons avec remise, puis agrège les résultats
* Idéal pour : jeux de données très petits, estimation de la stabilité du modèle
* Avantage : simule la possession de plus de données que disponibles
* Options à définir :
* **bootstrap\_train\_sample\_size**: La proportion de l'ensemble de données à rééchantillonner avec remise.
* **n\_iterations**: Nombre de bootstraps/divisions à créer. Un nombre d'itérations plus élevé peut réduire l'incertitude des estimations de performance.
4. **Défini par l'utilisateur**
* Spécifiez manuellement les indices d'entraînement/validation ou la logique de division personnalisée
* Idéal pour : données temporelles, schémas d'évaluation spéciaux
* Flexibilité : importer des partitions prédéfinies ou implémenter des règles uniques
* Options à définir :
* **train\_indices**: Liste des indices d'entraînement pour l'ensemble d'entraînement
* **test\_indices**: Liste des indices de test pour l'ensemble de test
#### **Paramètres généraux pour le nœud Diviser**
Avant d'exécuter votre expérience, configurez ces paramètres essentiels pour contrôler la manière dont vos données sont partitionnées :
**1. État aléatoire (`random_state`)**
* **Objectif :** Assure des divisions reproductibles en initialisant le générateur de nombres aléatoires avec une graine fixe.
* **Utilisation :**
* Saisissez une valeur entière (par ex., `42`) pour rendre les résultats des divisions cohérents entre les exécutions.
* Laissez vide pour des divisions véritablement aléatoires (non recommandé pour des expériences reproductibles).
**2. Colonnes de stratification (`stratify_columns`)**
* **Objectif :** Maintient la distribution originale des variables clés (par ex., étiquettes de classe) à la fois dans les ensembles d'entraînement et de test et évite des divisions biaisées pouvant fausser l'évaluation du modèle.
* **Exigences :**
* Au moins une colonne doit être sélectionnée.
* Choix courants : variables cibles ou colonnes démographiques (par ex., groupes d'âge, sexe).
**3. Utiliser des étiquettes pour la stratification**
* **Objectif :** Tire parti des [*Étiquettes de colonne*](https://medomicslab.gitbook.io/medomics-docs/v1-fr/design/input-module#feature-or-column-tagging-tools) ou [*Étiquettes de ligne*](https://medomicslab.gitbook.io/medomics-docs/v1-fr/design/input-module#sample-or-row-grouping-tools-subset-creation-tool) comme groupes de stratification.
* **Comment cela fonctionne :**
1. Activez cette option pour activer la stratification basée sur les étiquettes.
2. Les étiquettes disponibles à partir de votre ensemble de données se rempliront automatiquement dans un menu déroulant.
3. Sélectionnez une ou plusieurs étiquettes à utiliser comme critères de stratification.
* **Notes clés :**
* Compatible avec `stratify_columns` (peut être utilisé simultanément).
* S'il n'existe aucune étiquette, le système affichera un avertissement, mais cela n'affectera pas l'exécution.
* Les étiquettes sont particulièrement utiles pour des schémas de stratification complexes (par ex., scénarios multi-étiquettes).
{% hint style="warning" %}
Contrairement aux autres nœuds, le nœud Diviser n'a pas d'options supplémentaires
{% endhint %}
Répartition du nœud Diviser
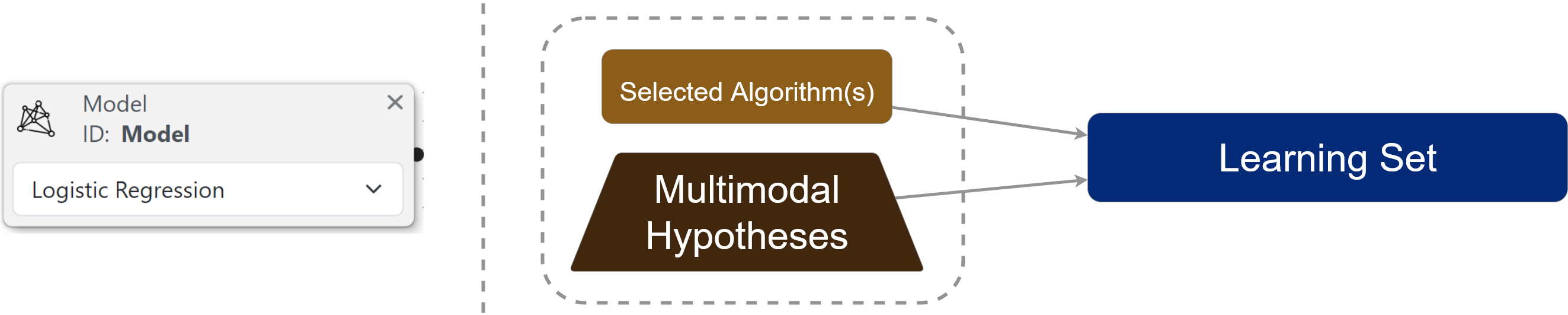
## Nœud Modèle : **Sélectionnez et configurez votre algorithme d'apprentissage automatique**
Ce nœud vous permet de sélectionner et personnaliser votre modèle d'apprentissage automatique. Les modèles disponibles et leurs paramètres correspondent directement à :
* Le `paramètre` estimator [options `dans` fonction](https://pycaret.readthedocs.io/en/latest/api/classification.html#pycaret.classification.create_model)
* [create\_model()](https://scikit-learn.org/stable/)Les implémentations complètes de modèles de Scikit-learn
Le nœud Modèle est utilisé dans l'étape de sélection d'algorithme, comme montré ci-dessous :
Répartition du nœud Modèle
**À la page suivante, vous en apprendrez davantage sur la Boîte d'Entraînement, qui vous aidera à définir le processus d'entraînement de votre expérience.**