
la boîte d'analyse
la boîte d'analyse


Résultats pour le nœud Jeu de données

Résultats pour le nœud Nettoyage

Résultats pour le nœud Division

Résultats pour le nœud Modèle

Résultats pour le nœud Combiner les modèles

Résultats pour le nœud d'analyse
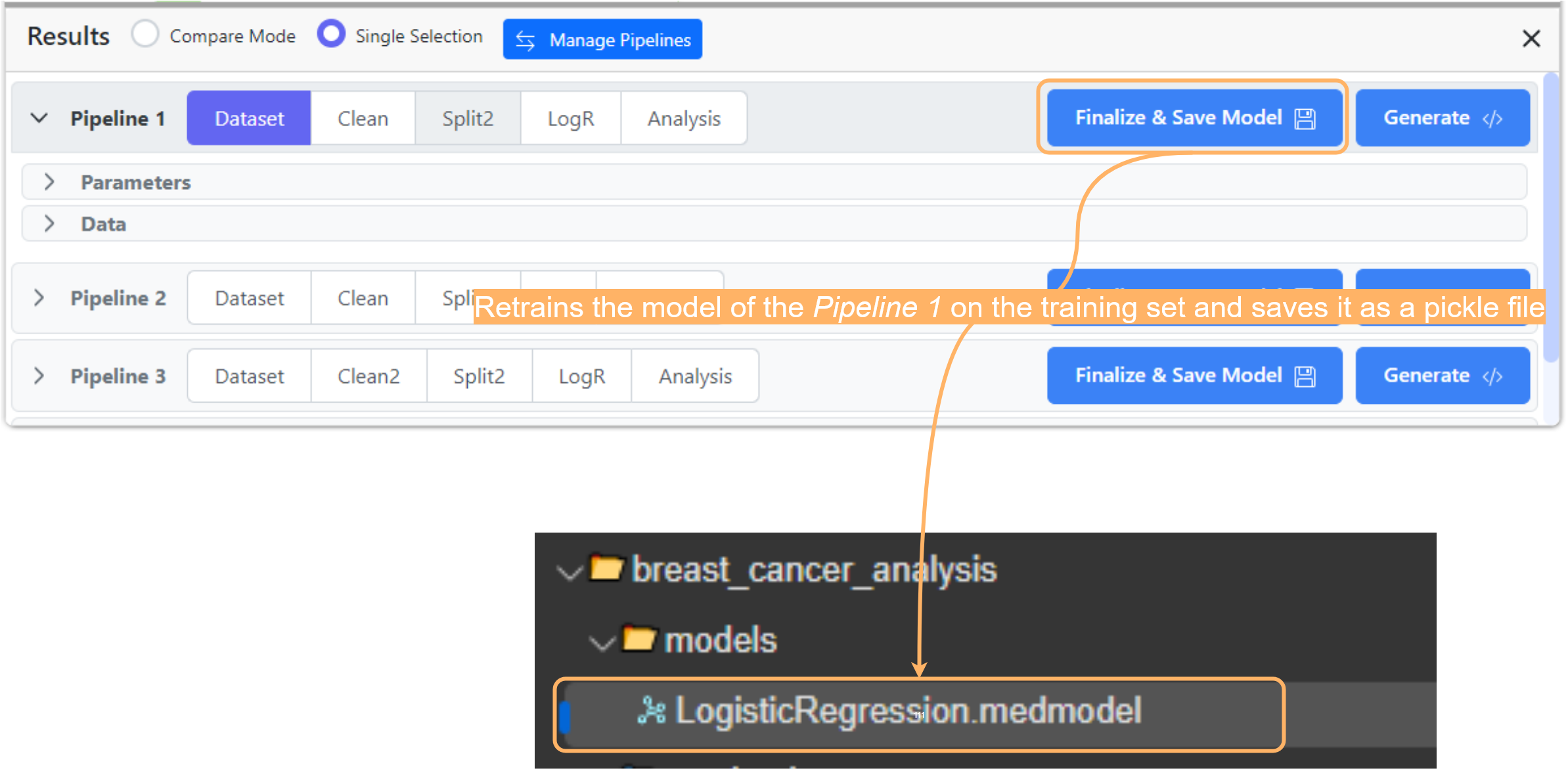
Comment finaliser et enregistrer un modèle dans un pipeline donné


Comment générer un Notebook pour un pipeline donné

Différentes options pour ouvrir un Jupyter Notebook généré
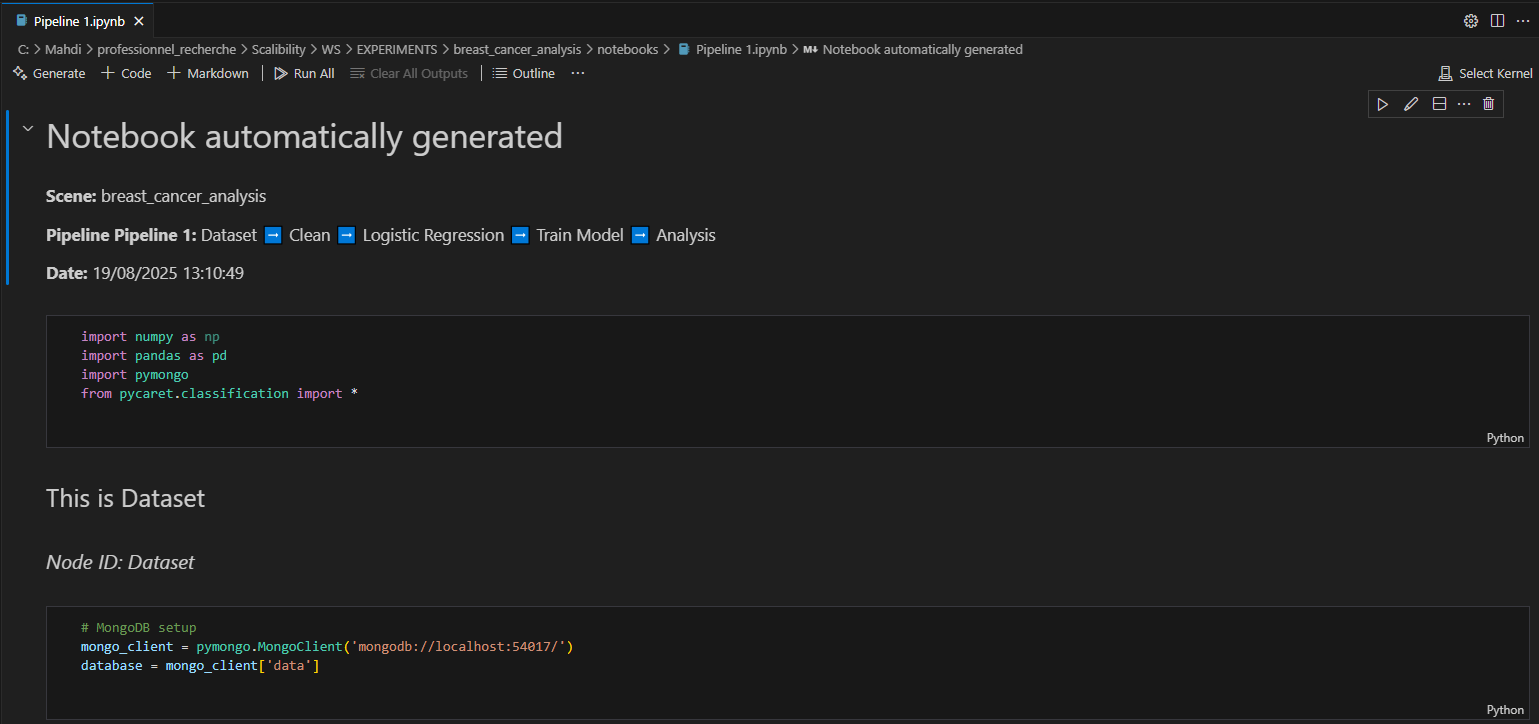

Exemple d'un Jupyter Notebook généré

Comment accéder et utiliser le panneau Gérer les pipelines

Illustration de l'utilisation de la case à cocher du nœud

Illustration de la fonctionnalité de mise en évidence pour différentes interactions

Répartition du mode Analyse