# medmodel
### **Qu'est-ce qu'un objet MEDMODEL ?**
Un **`.medmodel`** fichier est une extension personnalisée utilisée au sein de la **plateforme MEDomics** pour représenter des modèles d'apprentissage automatique sérialisés et sauvegardés générés à partir des scènes analytiques de la plateforme.
Cet objet sert de conteneur complet pour tous les éléments essentiels liés à un modèle entraîné, y compris l'architecture du modèle, les paramètres d'entraînement, le pipeline de prétraitement, les caractéristiques sélectionnées et les métadonnées.
Son but est d'assurer **traçabilité**, **reproductibilité**, et **partage** entre différents modules ou institutions MEDomics, permettant un déploiement et une évaluation transparents et ouvrant la porte à la collaboration.
#### Avantages clés pour l'utilisateur
1. Inférence "Plug and Play" : Vous n'avez pas besoin de vous souvenir si vous avez normalisé vos données en utilisant `MinMaxScaler` ou `StandardScaler`. L'objet MEDMODEL le sait déjà.
2. Pas de prétraitement manuel : Vous pouvez fournir des données brutes "désordonnées" à un MEDMODEL ; le pipeline interne gère automatiquement le nettoyage.
3. Cohérence : Que le modèle s'exécute sur votre ordinateur portable ou sur un serveur hospitalier, la logique interne reste identique, garantissant la fiabilité clinique.
***
### Structure d'un objet MEDMODEL
Chaque objet MEDMODEL est un "cerveau" autonome composé de deux composants principaux :
#### 1. Pipeline Scikit-learn sérialisé
Le noyau du MEDMODEL est un [Pipeline Scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html) qui encapsule l'ensemble du flux de travail d'apprentissage automatique. Pensez à cela comme une chaîne de montage numérique : une fois qu'un point de données patient brut entre à une extrémité, il est automatiquement nettoyé, affiné et analysé avant d'atteindre la prédiction finale.
**Pourquoi utiliser un Pipeline ?**
Pour les lecteurs novices en apprentissage automatique, le plus grand risque est la fuite ou la discordance des données. Si vous calculez la valeur moyenne d'une caractéristique (comme l'âge) sur vos données de test au lieu d'utiliser la moyenne issue de vos données d'entraînement, votre modèle "triche" essentiellement en regardant l'avenir. Un pipeline empêche cela en "gelant" la logique apprise lors de l'entraînement.
**Le pipeline inclut :**
* **Étapes de prétraitement** (La "mémoire" du modèle) : Cela inclut la normalisation, la mise à l'échelle des caractéristiques et l'imputation des valeurs manquantes.
* *L'avantage des statistiques stockées :* Imaginez que vos données d'entraînement avaient des valeurs manquantes dans la colonne "Cholestérol". Le pipeline calcule la valeur moyenne à partir des patients d'entraînement et la stocke. Lorsque vous utilisez le modèle sur un nouveau patient plusieurs mois plus tard qui a également une valeur de cholestérol manquante, vous n'avez rien à recalculer. Le pipeline applique automatiquement cette *moyenne précédemment stockée* aux nouvelles données. Cela garantit que les nouvelles données sont traitées exactement comme les données sur lesquelles le modèle a été construit.
* **Sélection et transformation des caractéristiques** : Toute logique utilisée pour choisir les "meilleures" caractéristiques (comme les méthodes FDA ou FSR mentionnées précédemment) est sauvegardée. Le modèle "se souvient" des variables spécifiques importantes, vous n'avez donc pas à filtrer manuellement vos feuilles Excel avant de les fournir au modèle.
* **Estimateur entraîné** : Le classificateur ou régresseur final (par exemple, XGBoost, RandomForest). Parce qu'il se trouve à l'intérieur du pipeline, l'estimateur ne voit que des données parfaitement préparées par les étapes précédentes.
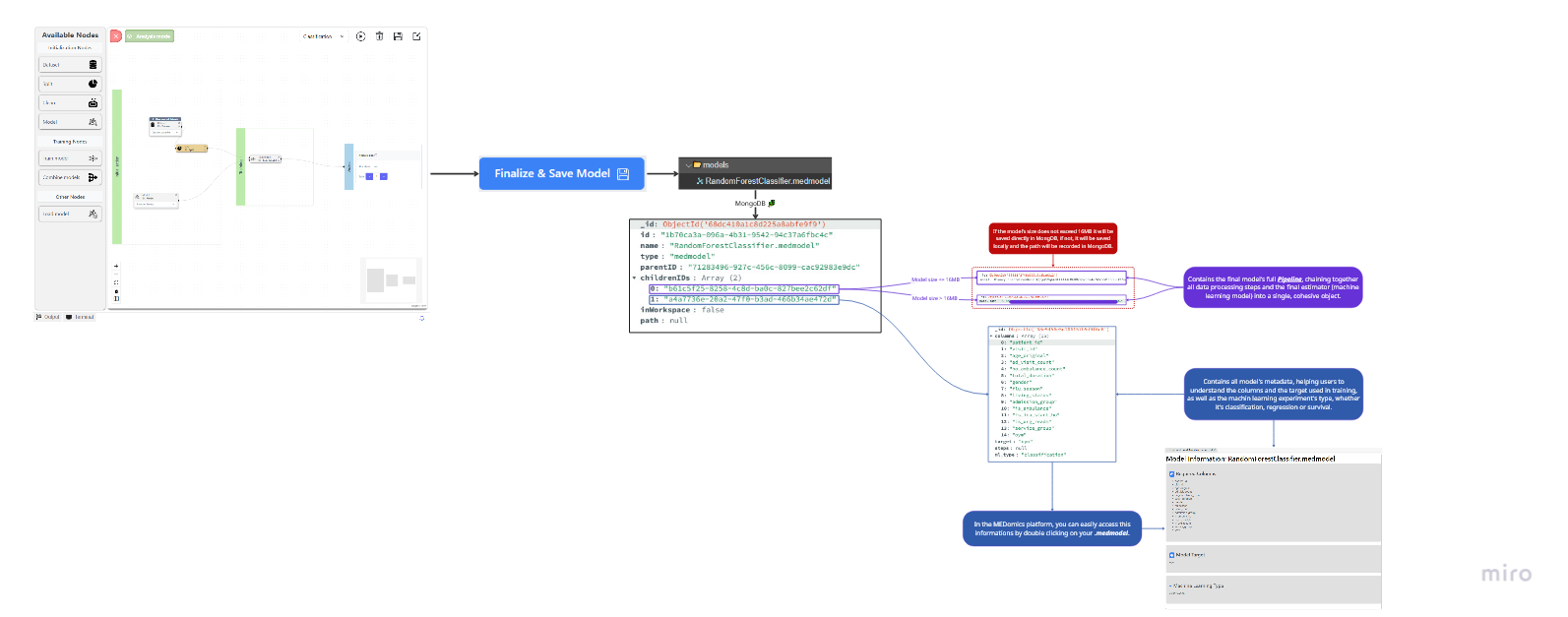
**Détails de stockage**
* Si le fichier de pipeline sérialisé (format pickle) est **≤ 16 Mo**, il est stocké **directement dans MongoDB**.
* S'il **dépasse 16 Mo**, il est stocké **localement sur le serveur**, et l'entrée MEDMODEL dans MongoDB référence le **chemin de fichier absolu**.
***
#### **2. Dictionnaire de métadonnées du modèle**
Un dictionnaire compagnon contient des informations détaillées décrivant le modèle, ses entrées et le contexte d'entraînement. Ces métadonnées garantissent la reproductibilité et facilitent la compréhension de la provenance et de l'objectif du modèle.
Les principaux champs de métadonnées incluent :
* **`model_variables`** – La liste finale des colonnes du jeu de données (caractéristiques) utilisées pendant l'entraînement.
* **`target_variable`** – La variable dépendante que le modèle prédit.
* **`ml_type`** – Spécifie si le modèle est destiné à la **classification** ou **régression**.
Le schéma suivant résume la relation entre les composants MEDMODEL :
```
┌────────────────────┐
│ MEDMODEL │
│ (objet .medmodel) │
└────────┬───────────┘
│
├──► Pipeline Scikit-learn (Pickle)
│ • Prétraitement
│ • Sélection des caractéristiques
│ • Modèle entraîné
│
└──► Dictionnaire de métadonnées
• Caractéristiques
• Cible
• Type de modèle (Classification/Régression)
```
***
La figure suivante résume le processus de création d'un objet MEDMODEL :
*Pour la vue du diagramme original, cliquez* [*ici*](https://medomicslab.gitbook.io/medomics-docs/v1-fr/contributing#the-medomics-platform-architecture)*.*