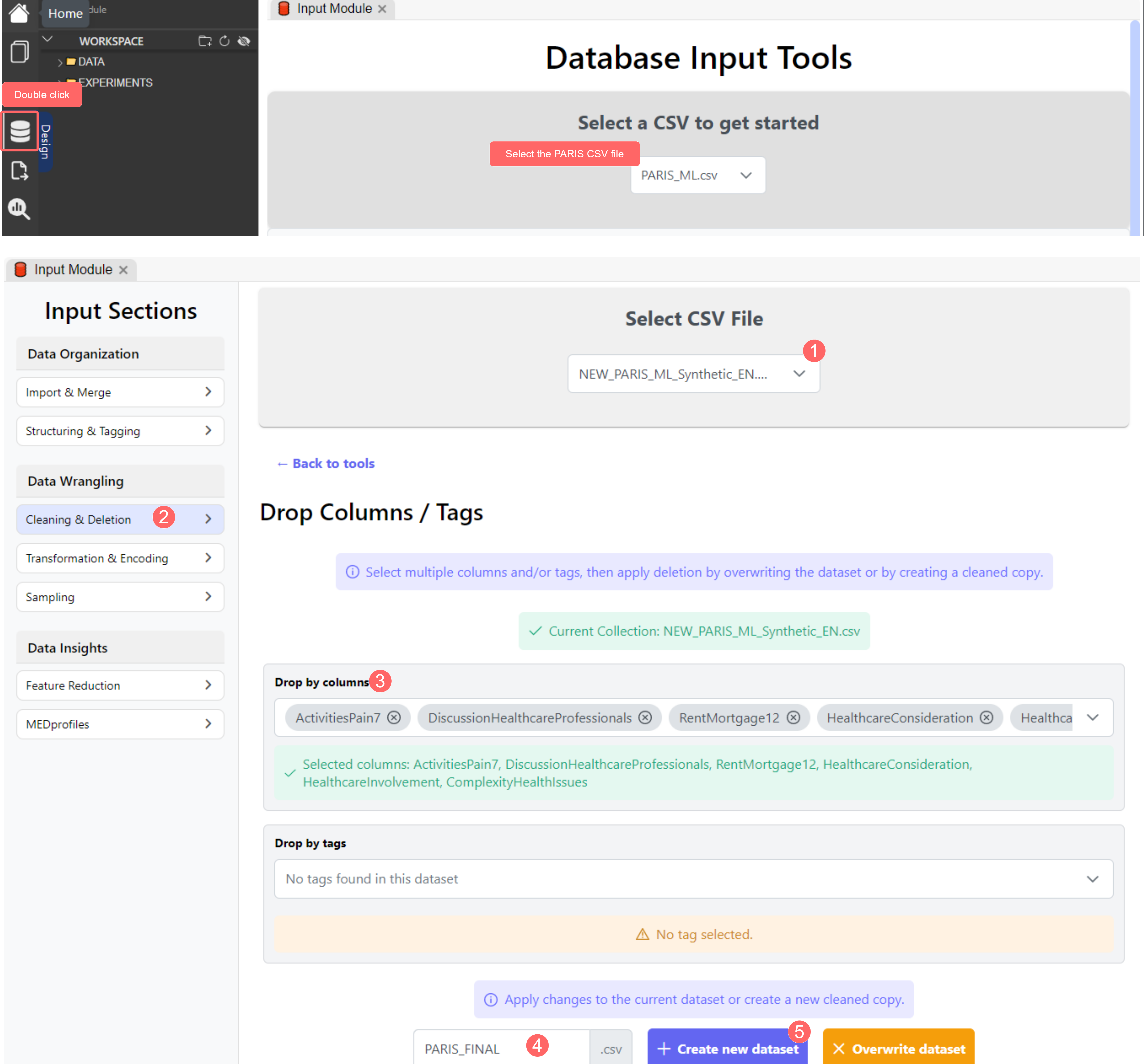
Fig. 20 - Comment supprimer des colonnes du CSV PARIS
Fig. 20 - Comment supprimer des colonnes du CSV PARIS
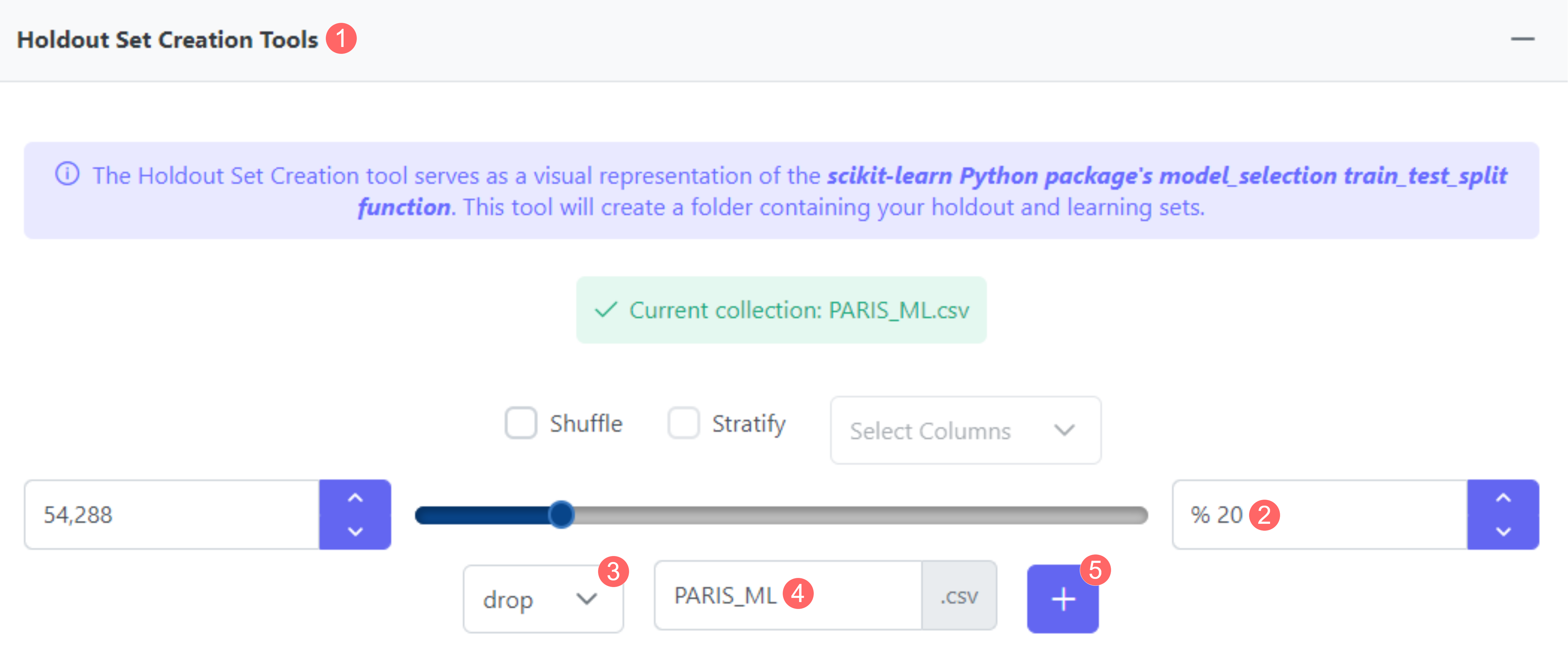
Fig. 21 - Créer un ensemble de validation pour notre ensemble final PARIS
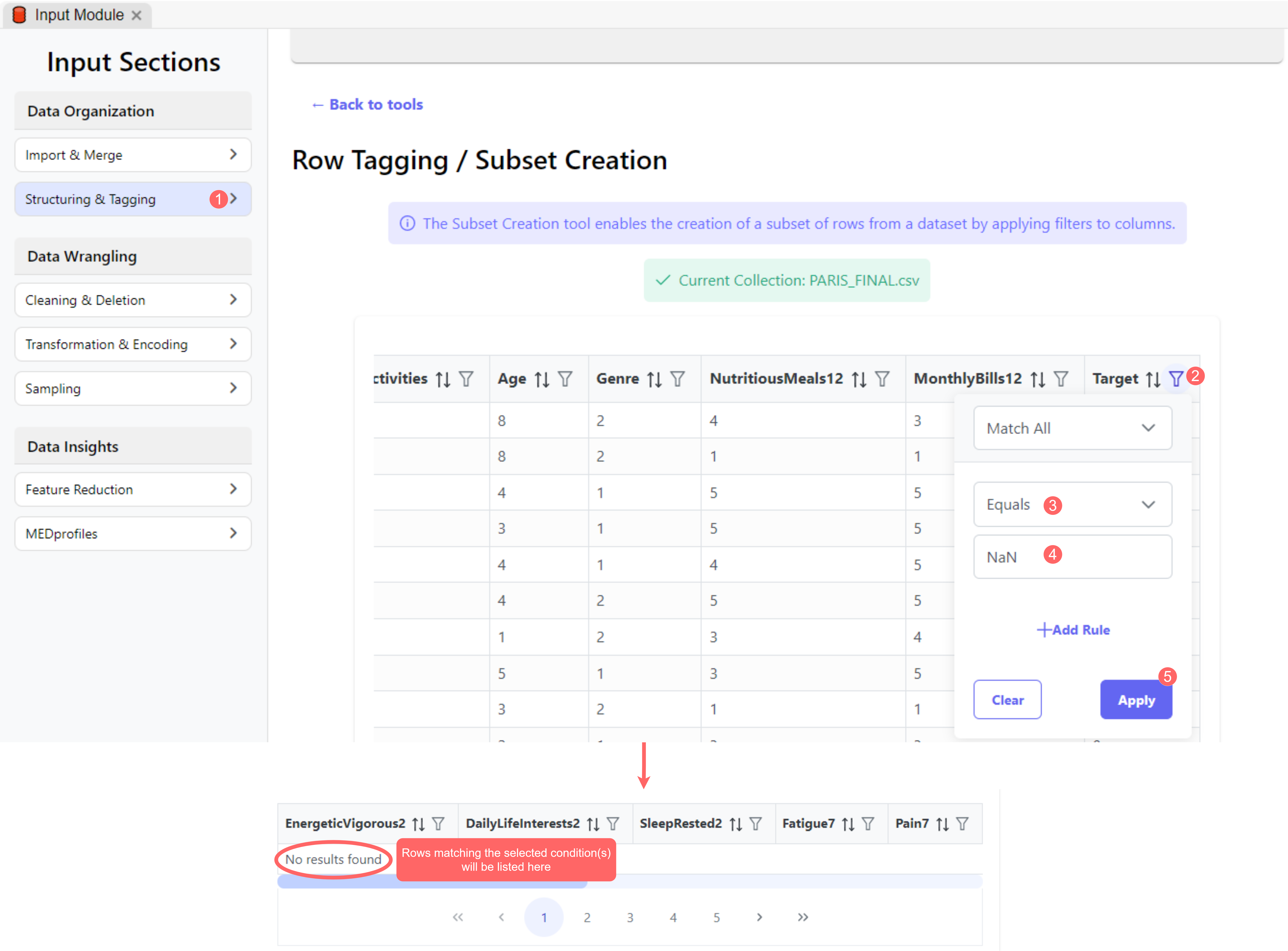
Fig. 22 - Comment supprimer les valeurs cibles NaN de l’ensemble PARIS.