.png?alt=media&token=78eaee3a-6189-4df0-8557-c268ef81bf1b)
Aperçu de la scène
Aperçu de la scène

Créer la scène "homr_scene"

dossier homr_scene dans Experiments

Configuration des nœuds Dataset

Configuration des nœuds Dataset
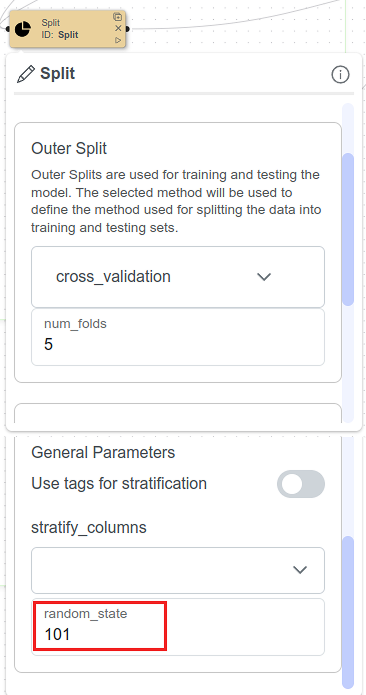
Configuration du nœud Split

Configuration des hyperparamètres du modèle
.png?alt=media&token=747a79a1-11d3-42ae-abb2-a3ceec36e422)
Configuration du nœud Train Model
.png?alt=media&token=5219648e-bc0b-4a93-9c67-a4715f79cf27)
Grille de réglage personnalisée pour notre modèle
.png?alt=media&token=8f4037de-78bb-4305-a590-affab986c613)
Options Tune Model
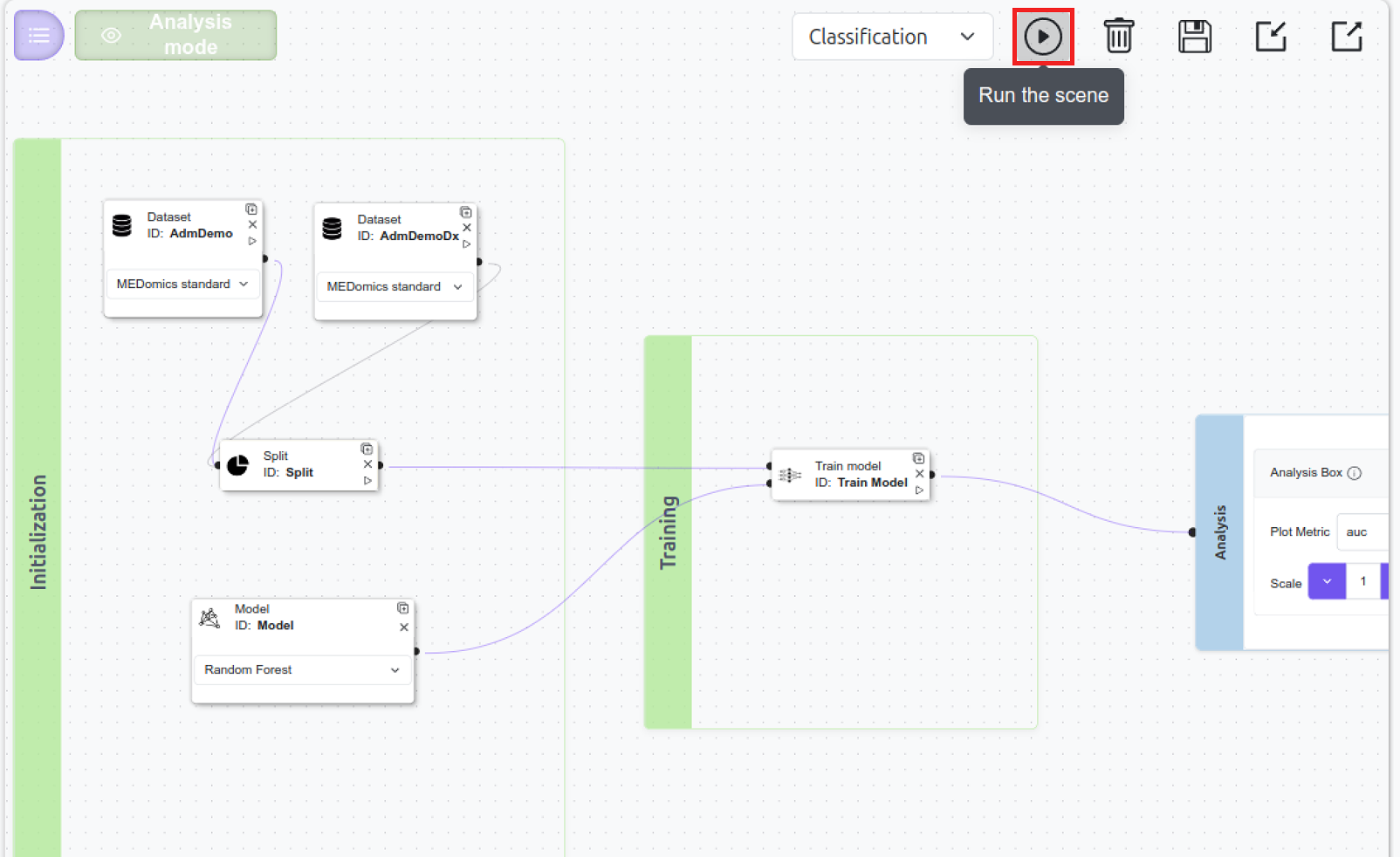
Exécuter la scène
.png?alt=media&token=15ad0dc8-9f33-4db8-b256-52416d3971dd)
Résultats du pipeline en mode Analyse

Statistiques des métriques pour le modèle AdmDemo
.png?alt=media&token=2af41fa5-6e5e-4edc-8a7f-9b3bd61ca146)
Statistiques des métriques pour le modèle AdmDemoDx

Résultats AdmDemo et AdmDemoDx